




Institute for Analytics and Data Science
Our research

A history of pioneering new techniques
At Essex University, we have a long history in data science. Since the 1960s, our pioneering researchers have helped the world make the most of the opportunities science and technology can bring.
Essex is one of the first three UK universities to house a central research activity in artificial intelligence (AI). We’ve been working in AI, gamification, machine learning and understanding complex systems for five decades.
Building on such strong foundations, IADS scientists lead the way in the next generation of computational and analytical methods to derive powerful insights from data.
Since its inception in 2014, IADS has helped us increase the reach and impact of our research by providing a unique perspective on data and analytics.
Our researchers work together, crossing disciplinary boundaries, challenging conventional approaches, and using data to enhance our knowledge of individuals and society.
Our research areas
AI & Decision Making
This area represents all IADS activities related to traditional AI (e.g. logic), topics that are linked to complex systems (e.g. include multi-agent learning, reinforcement learning and game theory) and areas around creating optimal institutions that promote correct decision making (e.g. mechanism design).
Machine Learning and Statistical Learning
We work with both structured (e.g. tabular) and unstructured (i.e. text) data to help gain insights. The scope of our work ranges from the very applied to foundational mathematics.
Data Protection and Cybersecurity
Our work in this area varies from data privacy governance and data breach management, to reasoning techniques and algorithms for discovery and management of security attacks and threats.
Analytics and Visualisation
This area represents our analytical and computational work for the discovery, analysis and interpretation of data to inform decisions and visualisation of complex and multidimensional data.
Ethics and Legal
Our work in this area focuses on understanding the ethical and legal dimensions of data usage, data science and of the relevant technologies (e.g. machine learning, AI) and explores fairness for the benefit of society.
Project showcase











IADS Fellows research projects
Are you passionate about your research field? Are you ambitious to develop your academic career? Do you aspire to make a difference? Find out more about our unique research fellowship programme.

More about Lee's research
Providing trustworthy and energy-efficient AI solutions
Incorporating numerical linear algebra properties into a machine learning framework
Research summary
Dr Lee’s research is focused on minimizing energy consumption and CO2 emissions by co-optimising machine learning models across algorithm, arithmetic and dataflow.
AI is used everywhere, consuming astronomical energy and producing massive CO2 emissions. It is expected that energy consumption and CO2 emissions from AI usage will increase rapidly.
His core research skillset includes incorporating numerical linear algebra properties into machine learning frameworks, analysing the accuracy and stability of machine learning models with respect to dynamically varying environments, and providing energy-efficient machine learning solutions based on the findings from the analysis.
Research challenge
It is challenging to deploy high-performance machine learning models on computing devices under limited computational resources and energy (e.g., IoT-based AI). For example, if you would like to improve the accuracy of a machine learning model, more computational resources and energy are generally required. To improve the resource efficiency of a model, the accuracy and stability of machine learning models can assist in selecting the least sufficient models given the dataset.
Research focus
Dr Lee is working to establish a "Mathematical and Computational Foundation of Trustworthy Energy-Efficient Machine Learning (TEEM)."
This aims to provide trustworthy energy-efficient AI solutions by incorporating numerical linear algebra properties into a machine learning framework to impact society, the economy, and the environment, as shown in Figure 1.
For example, the numerical linear algebra community analyzes the effects of numerical behaviours on accuracy and stability quantitatively, while the machine learning community prefers qualitative understanding. Therefore, the analysis approaches used by the two communities complement each other, and the combined analysis will assist in building the ecosystem towards "Trustworthy AI" in terms of transparency, safety and explainability by clarifying the effects of numerical behaviors (e.g., the perturbation on input) on the accuracy and stability of machine learning.
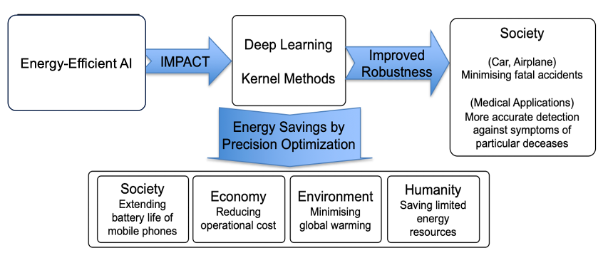
Figure 1. Impact of MACFEEM on Society, the Economy and the Environment

More about Lina's research
Decision making under complex and uncertain service-oriented settings
Addressing the challenges related to selecting and composing self-interested interaction partners in large-scale service-oriented settings.
Dr Barakat is interested in building AI solutions for complex applications (e.g. supply chain) that rely on services from multiple autonomous service providers. This requires algorithms that consider the preferences and incentives of individuals, and can solve problems inherent in such complex applications, such as trust issues, dynamic markets and societal needs.
Research challenge
Dr Barakat’s primary research focuses on addressing the challenges related to selecting and composing self-interested interaction partners in large-scale, dynamic, heterogeneous, and unreliable service-oriented settings.
Research focus
Her research has focused on designing self-optimising and self-healing service composition algorithms under high degrees of dynamism and uncertainty, and under various correlations among the interacting parties.
Her research has also involved predicting the performance of service providers in such settings. This includes applying machine learning with drift handling mechanisms to provide personalised and relevant predictions of service characteristics, and enriching trust and reputation assessment models with provenance knowledge.
She has also investigated a reputation-driven incentivisation framework to encourage self-interested providers to report truthful provenance information of their service provisions.
Notable outcomes
She is currently writing a research proposal (as a PI) that aims to improve social benefits in a marketplace, by providing socially responsible service compositions to users.
More about Amanda's research
Sociolinguistics, language attitudes, language variation and change
Researching how language is used, evaluated and discussed in society
Dr Amanda Cole is interested in why and how people speak differently to each other, how languages change, the ways in which people are perceived or judged based on their accent, and how linguistic behaviour or commentary about language reflect and interact with society.
She has particularly focused on the accents of south-east England.
Research challenge
There has been a lack of sociolinguistic research in south-east England relative to some other regions.
There have not previously been large-scale studies showing the different ways of speaking in this region, how these accents vary between people, and the patterns of judgements and evaluations based on different ways of speaking.
Research focus
Dr Cole’s research aims to document and understand the different ways of speaking in south-east England.
She has previously researched the influence of Cockney accents in Essex, showing that what we now think of as an Essex accent has been very influenced by Cockney. She has shown that dialect levelling is happening in this area, meaning that young people are beginning to speak more similarly to each other than older generations.
She has also looked at language attitudes in south-east England in terms of intelligence, friendliness and trustworthiness.
She runs The Accentism Project and her research aims to raise awareness of and combat accentism – the way that people are judged, mocked or commented on based on their accent.
Notable outcomes
Her research has revealed that people from Essex or London and/or from working-class or ethnic minority backgrounds were judged most harshly based only on their accent.
Her study shows that based only on their accent, lower-working-class people were judged to be on average 14% less intelligent, 4% less friendly and 5% less trustworthy than upper-middle-class people. People from ethnic minority backgrounds were evaluated as 5% less intelligent than white people, regardless of class.
Compared with other areas of the south-east, negative judgments were made about people from London and Essex, places where the accents have been routinely devalued.

More about David's research
Data science approaches for new insight in microbial ecology
Understanding and predicting the impacts of environmental change on Earth’s biodiversity
Human activities are changing the Earth at unprecedented rates. Climate change, land-use change and pollution are threatening the ecosystems and organisms upon which we so desperately depend.
Microbial organisms play an underappreciated role in the health of our environment. Everything from soil health, crop productivity, water quality and greenhouse gas production is intimately linked to the diversity and activity of microorganisms in the environment.
Research challenge
Understanding and predicting the impacts of environmental change on Earth’s biodiversity is a critical challenge if we are to ‘bend the curve’ of biodiversity loss.
Microbial ecology is experiencing a ‘golden age.’ Technological developments in DNA sequencing mean that we can now generate enormous quantities of genomic data to understand which microbes are present in the environment and what they may be doing.
However, these advances have shifted the ‘bottleneck’ in this research field from generating data to making sense of it.
As datasets continue to grow in size, increasingly complex analytical methods are required to extract valid conclusions from the data deluge. This includes both bioinformatic methods required to transform DNA sequences into information, and statistical methods needed to tease out ecological patterns and relationships.
Dr Clark’s research involves applying cutting edge bioinformatic and statistical tools to highly complex genetic and genomic datasets to understand the potential impacts of environmental change on the microbial communities that support ecosystem and human health.
Research focus
As a microbial ecologist, most of Dr Clark’s research is dedicated to understanding how environmental changes may alter the diversity, functionality and composition of environmental microbial communities, and how such changes may propagate through to the functioning of Earth’s ecosystems.
His research largely revolves around the application of data-science tools and approaches to gain new understanding in microbial ecology.
Notable outcomes
A recent focus of Dr Clark has been on the microbial communities in rivers that cycle nitrogen, a key nutrient for all life on Earth. The composition and activity of these microbes determines whether nitrogen is lost to the atmosphere as a harmless gas, transformed to a harmful greenhouse gas, or retained in the river where it can cause catastrophic toxic algal blooms.
Through advanced statistical modelling, his recent research has revealed new relationships between the composition of these nitrogen cycling microbial communities and geology, providing us with a potential way of ‘scaling-up’ our predictions about microbial ecology beyond single rivers, to much greater spatial scales.

More about Jennifer's research
Biological machine learning
Using computational methods to answer basic questions about the evolution of life
Research summary
Dr Hoyal Cuthill is interested in using computational methods to answer basic questions about the evolution of life.
She sees two main ways in which data science can enable fundamental scientific discoveries in sciences such as evolutionary biology. Firstly, statistical methods allow us to test qualitative theories and hypotheses, such as those proposed by the founders of evolutionary biology.
Secondly, new methods such as machine learning give us the power to analyse biological systems at real-world scales of diversity and complexity. This can help us to develop a new understanding of the evolutionary process and how it works from small to large scales.
Research challenge
When it comes to understanding how whole organisms evolve, from bacteria to humans, the genetic and genomic eras have provided one piece of the puzzle - the genetic code.
Now we can use machine learning to fill in a new piece, by quantitatively comparing large and complex samples of the overall phenome, the total organism. This allows us to answer deceptively simple questions, such as just how similar is one butterfly’s wing to another?
By measuring the similarity between individual animals and across species we can test how much their phenotypes have evolved, gaining new insights into the potential causes and outcomes of phenomic evolution.
Research focus
Dr Hoyal Cuthill conducts computational and mathematical studies of a range of theoretical and real evolutionary systems, including examples from early evolutionary history to living groups.
Her research considers a number of different, but conceptually linked questions. For example, what prompts the evolution of new species, is it the extinction of others, or spontaneous biological events? Our answer, both, and a continuum in between, was published as a paper in the journal Nature in 2020.
Notable outcomes
In other recent and new research, Dr Hoyal Cuthill set out to measure how much butterfly colours, patterns and shapes evolve in response to different selection pressures, including mimicry for mutual protection.
Our analyses of mimicry, published in Science Advances in 2019, provide real-world evidence to suggest that evolution for mutual benefit can be so strong it dominates overall visual appearance, validating the first theoretical model in evolutionary biology, proposed by Fritz Müller in 1879.
More about Annalivia's research
The use of machine learning in the social sciences
Conducting causal analysis from observational longitudinal data
Research summary
Dr Annalivia Polselli, in collaboration with Dr Spyros Samothrakis (IADS) and Prof Paul Clarke (ISER), is developing a methodology for estimating the heterogeneous average treatment effects from observational panel/longitudinal data using high-performance machine learning.
The project is part of a wider MiSoC programme committed to bringing data science in social sciences.
Research challenge
The main objective of applied social scientists is to consistently estimate the causal impact of a treatment (e.g. policy or reform) on an outcome of interest. This consists of comparing the average outcomes of treated units with control units. However, no unit can be observed in the treated and control group simultaneously. This is known as the “fundamental problem of causal inference”.
The effect of an intervention is unlikely to be homogeneous among the targeted population (e.g. individuals, regions, countries) but it might vary across units exposed to the treatment. There is a growing interest in estimating heterogeneous effects of units with a large set of individual characteristics. This can be done with the estimation of the Conditional Average Treatment Effects (CATE).
More accurate estimates can be obtained with machine learning techniques, that provide valid confidence intervals for statistical inference. However, the use of machine learning introduces two types of bias: the first due to overfitting that can be solved with sample splitting, and the second due to regularization that can be handled via orthogonalizing the estimator.
Their method builds on this theoretical framework.
Research focus
Social scientists are interested in conducting causal inference exercises on the phenomenon of interest so Dr Polselli, with Dr Samothrakis and Prof Clark, are working on an estimator for heterogeneous average treatment effects using machine learning tools.
They are developing a methodology for estimating the dependence of average causal effects on subjects’ time-varying characteristics from observational panel/longitudinal data. They will contribute to the recent literature on causal inference literature on causal random trees, causal random forest, and doubly debiased estimators.
In her doctoral research, she examined estimating valid statistical inferences in panel data models. She focused on panel data sets with a small cross-sectional sample, heteroskedasticity, and good leveraged, which is a structure common in the macroeconomic country-level studies and experimental works, characterised by a relatively small number of cross-sectional units.
The presence of heteroskedasticity and good leveraged data undermines conventional cluster-robust standard errors, leading to the over-rejection of the null hypothesis. Jackknife-type standard errors mitigate the downward bias of conventional inference.
As an applied Econometrician, she has expressed an active interest in documenting gender gaps in the labour market and delving into the reasons behind their existence, contributing to projects close to labour and gender economics.
Notable outcomes
A recent paper "An International Map of Gender Gaps" revisits stylized facts on female labour force participation, employment and unemployment in high-income and middle-low income countries. The working paper gained the media’s attention and was cited in the Italian economic newspaper Il Sole 24 Ore.
Dr Polselli and her co-authors are currently at the very early stage of the project on the use of machine learning for panel data models. They plan on publishing the proposed methodology in a peer-reviewed journal and making the computational package available in several programming languages (i.e., Python, R and Stata), building a bridge between social and computer sciences.
In addition, she is writing up the papers related to the topics covered in her PhD with the ultimate goal to publish them in peer-reviewed journals.

More about Akitaka's research
Computational analysis of political texts
Analysing political texts using natural language processing methods
Research summary
Dr Matsuo’s research is primarily concerned with analysing political texts using natural language processing methods to gain some insight. He uses text from a variety of sources, such as social networking sites, parliamentary proceedings, and reports from governments and international organizations.
Some examples of projects he is currently working on are:
- Reviewing discussions take place on social networking sites regarding recent trade conflicts between Japan and Korea and how they relate to political positions and the history of the two countries.
- Exploring the relationship between candidates' gender and the expression of emotions using tweets from British election candidates
- Analysing emotions in legislators' speeches in parliament using Japan as an example.
Research challenges
Much of Dr Matsuo’s research has been using the text data in non-English languages, and there are various obstacles to targeting these languages. This is because of the limited resources available for minor languages.
It would be useful to have a dictionary of emotional words to detect sentiments, but such a dictionary is not readily available. Also, it is essential for machine learning applications to have text that has been classified by human readers, but there are limited services available for such purposes.
Solutions
To answer these challenges Dr Matsuo is creating a sentiment dictionary in a minor language that can be used by researchers and practitioners. He is also involved in developing a method of automated labelling of texts by substituting the work of human readers with methods utilizing the characteristics of political and social systems.

More about Nina's research
Exploring the Intersection of Sociolinguistics, Speech Technologies, and AI Ethics
Research Summary
Nina is a researcher at the intersection of sociolinguistics, speech technologies, and AI ethics, with a keen interest in understanding the dynamic relationships between language variation, technological development, and societal impacts. Her work explores how speech technologies influence and are influenced by speech communities, while also addressing the broader socio-technical contexts in which these technologies operate. Nina's research is informed by her background in sociolinguistics and computer science, with a focus on the ethical implications of machine learning and artificial intelligence. She aims to foster interdisciplinary collaboration, integrating insights from science and technology studies, sociology, and political studies to address complex challenges at the nexus of technology and society.
Research Challenge
The primary research challenge Nina addresses is the complex interplay between language variation and technological development, particularly in the context of speech technologies. As these technologies become increasingly pervasive, they have the potential to both reflect and shape linguistic diversity in profound ways. Nina's work critically examines how speech technologies, such as speech recognition and synthesis systems, impact speech communities, potentially reinforcing or disrupting existing language hierarchies. Moreover, she explores the ethical implications of these technologies, particularly in relation to issues of bias, fairness, and inclusivity. By situating her research within broader socio-technical contexts, Nina seeks to contribute to the development of more equitable and socially responsible technological systems.
Research Focus
- Language Variation and Change: Investigating how speech technologies interact with linguistic diversity, including the ways in which these technologies may privilege certain language varieties over others, thereby influencing language change and variation.
- Impact of Speech Technologies on Speech Communities: Exploring the social and cultural effects of speech technologies on different speech communities, particularly those that are marginalized or underrepresented in technological development.
- AI Ethics and Socio-technical Contexts: Analyzing the ethical implications of machine learning and AI, with a particular emphasis on understanding the broader socio-technical contexts in which these technologies are developed and deployed. This includes examining the power dynamics and social structures that shape technological innovation and its impacts on society.
- Interdisciplinary Collaboration: Promoting collaboration across disciplines, including sociolinguistics, computer science, sociology, and political studies, to address the complex challenges posed by the intersection of language, technology, and society. Nina is committed to fostering sustainable, anti-racist, and supportive environments for learning, working, and living, both within academia and in the broader community.




